This chapter is a description of the file formats used by . We’ll be using EBNFs to describe the format below. Here are some rules and types of rules we leave out, and prefer to describe informally:
<alpha-numeric>
<string-literal> (stuff between quotes)
<opt-whatever> (systematically... "" | <whatever>)
<keyword-whatever> (systematically.. "whatever" ":")Any format file can include comments. Comments start %. There is also the option of using /* */ for embedded comments.
The following are reserved words. You should not use them as variable names. NB: the reserved words are indicated below between quotes; eg. “semantics”. You can ignore C pre-processor noise such as #define SEMANTICS
For reference, we include the Parsec LanguageDef that we use to implement the format.
TODO: literate Haskell
Below are some examples of variables and constants. Note that we support atomic disjunction of constants, as in Foo|bar|baz and of constraints to variable values, but not of variables themselves.
anonymous variable ?_or_variables ?Xor?xconstrained variables ?X/foo|baror?x/foo|Barconstants Foo,foo,"Joe \"Wolfboy\" Smith", orFoo|barHere is an EBNF for GenI variables and constants
<value> ::= <variable> | <anonymous-variable> | <constant-disj>
<variable> ::= "?" <identifier> <opt-constraints>
<constraints> ::= "/" <constraints-disj>
<anonymous> ::= "?_" | "_"
<constant-disj> ::= <constant> (| <constant>)*
<constant> ::= <identifier> | <string-literal>
<identifier> ::= <alphanumeric> | "+" | "-" | "_"
<string-literal> ::= <double-quote> <escaped-any-char>* <double-quote>
<escaped-any-char> ::= "\\" | "\" <double-quote> | <char>TODO: explain the difference between atomic disjunction and fancy disjunction. TODO: update EBNF to point to fancy disjunction
In addition to variables and constants, also makes heavy use of flat feature structures. They take the form [foo:bar ping:?Pong], or more formally,
<feature-structure> ::= "[" <atttribute-value-pair>* "]"
<attribute-value-pair> ::= <identifier-or-reserved> ":" <value>
<identifier-or-reserved> ::= <identifier> | <reserved>A {semantics} is basically a set of literals. Semantics are used in to provide input (section {sec:geni-input-semantics}) and in the definition of lexical entries (section {sec:geni-lexicon}).
Notice that this is a flat semantic representation! No literals within literals, please. A literal can take one of two forms:
handle:predicate(arguments)
predicate(arguments)The arguments are space-delimited. Not providing a handle is equivalent to providing an anonymous one.
<semantics> ::= <keyword-semantics> "[" <literal>* "]"
<literal> ::= <value> : <identifier> "(" <value>* ")"
| <identifier> "(" <value>* ")"The semantic input can either be provided directly in the graphical interface or as part of a test suite.
The semantics is basically follows the format described above, but it can also be further constrained, see below.
Each literal may be followed by a boolean expression in square brackets denoting constraints on the lexical selection for that literal, for example
l0:chase(c d c) [ Passive | (Active & (~ Ditransitive) ]{Boolean expression syntax not supported yet. Use space-delimited conjunctions for now}
The syntax for expressions is defined in this EBNF:
<boolexp> ::= <identifier>
| <boolexp> & <boolexp>
| <boolexp> | <boolexp>
| ~ <boolexp>
| ( <boolexp> )See chapter {cha:paraphrase} for more details on how literal constraints are used.
Index constraints can be specified using a syntax similar to that used by feature structures, without the requirement that attributes be unique. To give an example, the input below uses an index constraint to select between two paraphrases in a hypothetical grammar that allows either the sentences “the dog chases the cat” or “it is the cat which is chased by the dog”.
semantics:[l0:chase(c d c) l1:dog(d) l2:def(d) l3:cat(c) l4:def(c)]
idxconstraints:[focus:d]Use of index constraints requires polarity filtering. See section {sec:polarity:idxconstraints} on how they are applied.
GenI accepts an entire test suite of semantic inputs that you can choose from. The test suite entries can be named. In fact, it is probably a good idea to do so, because the names are often shorter than the expected output, and easier to read than the semantics. Note the expected output isn’t used by itself, but external tools that “test” .
<test-suite> ::= <test-suite-entry>*
<test-suite-entry> ::= <opt-identifier> <semantics> <expected-output>*
<expected-output> ::= <opt-keyword-sentence> "[" <identifier>* "]"The lexicon associates semantic entries with lemmas and trees.
There are two ways to write the lexicon. We show the old (deprecated) way first because most of the examples are still written in this style.
le clitic (?I)
semantics:[]
le Det (?I)
semantics:[def(?I)]
livre nC (?I)
semantics:[book(?I)]
persuader vArity3 (?E ?X ?Y ?Z)
semantics:[?E:convince(?X ?Y ?Z)]
persuader v vArity3controlObj
semantics:[?E:convince(?X ?Y ?Z)]detester n0Vn1
equations:[theta1:agent theta2:patient arg1:?X arg2:?Y evt:?L]
filters:[family:n0Vn1]
semantics:[?E:hate(?L) ?E:agent(?L ?X) ?E:patient(?L ?Y)]You can have arbitrary strings in your lexical entries if you surround them in quote marks
"Joe \"the Boxer\" Stephens" Pn(?X)
semantics:[?E:name(_ ?X joe_stephens)]The semantics associated with a lexical item may have more than one literal
cher adj (?E ?X ?Y)
semantics:[?E:cost(?X ?Y) ?E:high(?Y)]A lemma may have more than one distinct semantics
bank n (?X)
semantics:[bank(?X)]
bank v (?E ?X ?D)
semantics:[?E:lean(?X,?D)]A semantics may be realised by more than one lexical entry (e.g. synonynms)
livre nC (?I)
semantics:[book(?I)]
bouquin nC (?I)
semantics:[book(?I)]<lexicon> ::= <lexicon-entry>*
<lexicon-entry> ::= <lexicon-header> <opt-filters> <semantics>
<lexicon-header> ::= <lemma> <family> <parameters>
| <lemma> <family> <keyword-equations> <feature-structure>
<parameters> ::= "(" <value>* <opt-interface> ")"
<interface> ::= "!" <attribute-value-pairs>*
<filters> ::= <keyword-filter> <feature-structure>The tree schemata file (for historical reasons, this is also called the macros file) contains a set of unlexicalised trees organised into families. Such “macros” consist of a
a family name and (optionally) a macro name
a list of parameters
initial or auxiliary
a tree.
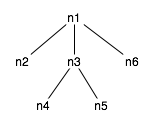
{Trees} are recursively defined structure of form node{tree*} For example, in the table below, the structure on the left should produce the tree on the right:
n1{
n2
n3{
n4
n5
}
n6
} |
{Nodes} consist of
a name
a type (optional)
either a lexeme, or top and bottom feature structures. Here are examples of the five possible kinds of nodes:
Here are some examples of nodes
n1 [cat:n idx:?I]![cat:n idx:?I] % basic
n3 type:subst [cat:n idx:?Y]![cat:n idx:?Y] % subst
n4 type:foot [cat:n idx:?Y]![cat:n idx:?Y] % foot
n5 type:lex "de" % coanchor
n2 anchor [cat:n]![cat:n] % anchor
n5 aconstr:noadj % node with a null-adjunction constraint (other than subst or foot)adj:post(?I) auxiliary
n0[cat:n idx:?I det:_]![cat:n idx:?I det:minus ]
{
n1 type:foot [cat:n idx:?I det:minus]![cat:n idx:?I det:minus]
n2[cat:a]![]
{
n3 anchor
}
}
adj:pre(?I) auxiliary
n0[cat:n idx:?I det:_ qu:_]![cat:n idx:?I det:minus ]
{
n1[cat:a]![]
{
n2 anchor
}
n3 type:foot [cat:n idx:?I det:minus]![cat:n idx:?I det:minus]
}
vArity2:n0vn1(?E ?X ?Y) initial
n1[cat:p]![]
{
n2 type:subst [cat:n idx:?X det:plus]![cat:n idx:?X]
n3[cat:v idx:?E]![]
{
n4 anchor
}
n5 type:subst [cat:n idx:?Y det:plus]![cat:n idx:?Y]
}<macros> ::= <macro>*
<macro> ::= <family-name> <opt-macro-name> <parameters> <tree-type> <tree>
<opt-semantics> <opt-trace>
<parameters> ::= "(" <value>* <opt-interface> ")"
<interface> ::= ! <attribute-value-pair>*
<macro-name> ::= <identifier>
<tree-type> ::= "initial" | "auxiliary"
<trace> ::= <keyword-trace> "[" <identifier>* "]"
<tree> ::= <node> | <node> "{" <tree>* "}"
<node> ::= <node-name> <opt-node-type> <node-payload>
<node-name> ::= <identifier>
<node-type> ::= <keyword-type> <core-node-type> | "anchor"
<core-node-type> ::= "foot" | "subst" | "lex"
<node-payload> ::= <string-literal> | <feature-structure> "!" <feature-structure>A morphinfo file associates predicates with morphological feature structures. Each morphological entry consists of a predicate followed by a feature structure. See morphology for more details.
(TODO: describe format)